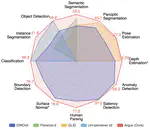
We introduce Argus, a compact and versatile vision foundation model designed to support a wide range of vision tasks through a unified multitask architecture. Argus employs a two-stage training strategy: (i) multitask pretraining over core vision tasks with a shared backbone that includes a lightweight adapter to inject task-specific inductive biases, and (ii) scalable and efficient adaptation to new tasks by fine-tuning only the task-specific decoders. Extensive evaluations demonstrate that Argus, despite its relatively compact and training-efficient design of merely 100M backbone parameters (only 13.6% of which are trained using 1.6M images), competes with and even surpasses much larger models. Compared to state-of-the-art foundation models, Argus not only covers a broader set of vision tasks but also matches or outperforms the models with similar sizes on 12 tasks.
Weiming Zhuang,
Chen Chen,
Zhizhong Li,
Sina Sajadmanesh,
Jingtao Li,
Jiabo Huang,
Vikash Sehwag,
Vivek Sharma,
Hirotaka Shinozaki,
Felan Carlo Garcia,
Yihao Zhan,
Naohiro Adachi,
Ryoji Eki,
Michael Spranger,
Peter Stone,
Lingjuan Lyu