Abstract
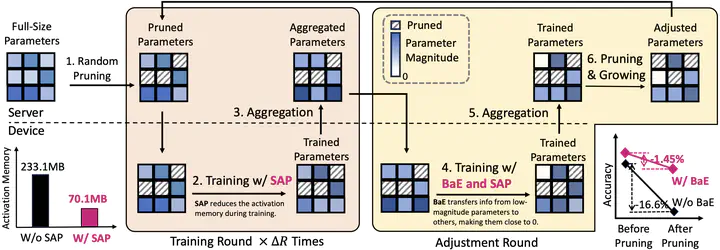
Federated learning (FL) promotes decentralized training while prioritizing data confidentiality. However, its application on resource-constrained devices is challenging due to the high demand for computation and memory resources to train deep learning models. Neural network pruning techniques, such as dynamic pruning, could enhance model efficiency, but directly adopting them in FL still poses substantial challenges, including post-pruning performance degradation, high activation memory usage, etc. To address these challenges, we propose FedMef, a novel and memory-efficient federated dynamic pruning framework. FedMef comprises two key components. First, we introduce the budget-aware extrusion that maintains pruning efficiency while preserving post-pruning performance by salvaging crucial information from parameters marked for pruning within a given budget. Second, we propose scaled activation pruning to effectively reduce activation memory footprints, which is particularly beneficial for deploying FL to memory-limited devices. Extensive experiments demonstrate the effectiveness of our proposed FedMef. In particular, it achieves a significant reduction of 28.5% in memory footprint compared to state-of-the-art methods while obtaining superior accuracy.
Weiming Zhuang
Senior Research Scientist
My current research interests include multimodal foundation model, federated learning, and computer vision applications.