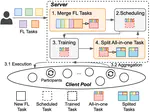
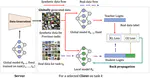
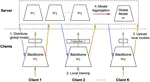
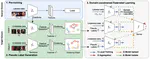
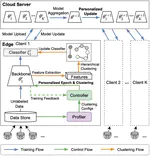
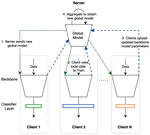
Federated Computer Vision Application

Weiming Zhuang
Senior Research Scientist
My current research interests include multimodal foundation model, federated learning, and computer vision applications.
My current research interests include multimodal foundation model, federated learning, and computer vision applications.