Collaborative Unsupervised Visual Representation Learning from Decentralized Data
Abstract
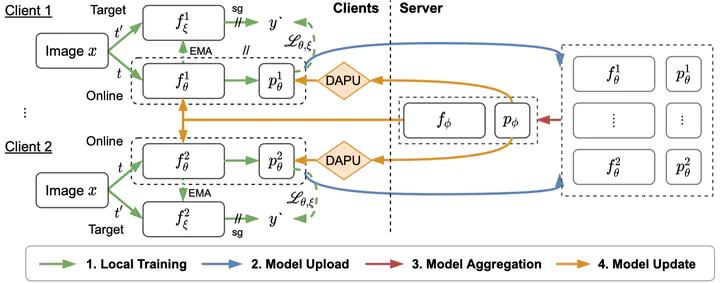
Unsupervised representation learning has achieved outstanding performances using centralized data available on the Internet. However, the increasing awareness of privacy protection limits sharing of decentralized unlabeled image data that grows explosively in multiple parties (e.g., mobile phones and cameras). As such, a natural problem is how to leverage these data to learn visual representations for downstream tasks while preserving data privacy. To address this problem, we propose a novel federated unsupervised learning framework, FedU. In this framework, each party trains models from unlabeled data independently using contrastive learning with an online network and a target network. Then, a central server aggregates trained models and updates clients' models with the aggregated model. It preserves data privacy as each party only has access to its raw data. Decentralized data among multiple parties are normally non-independent and identically distributed (non-IID), leading to performance degradation. To tackle this challenge, we propose two simple but effective methods: 1) We design the communication protocol to upload only the encoders of online networks for server aggregation and update them with the aggregated encoder; 2) We introduce a new module to dynamically decide how to update predictors based on the divergence caused by non-IID. The predictor is the other component of the online network. Extensive experiments and ablations demonstrate the effectiveness and significance of FedU. It outperforms training with only one party by over 5% and other methods by over 14% in linear and semi-supervised evaluation on non-IID data.
Weiming Zhuang
Senior Research Scientist
My current research interests include multimodal foundation model, federated learning, and computer vision applications.