Optimizing Performance of Federated Person Re-identification: Benchmarking and Analysis
Abstract
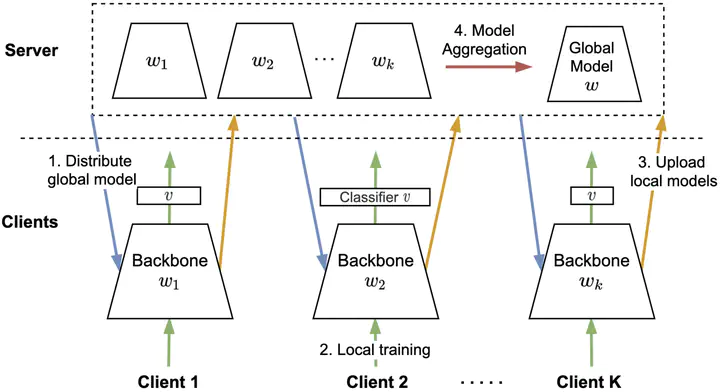
The increasingly stringent data privacy regulations limit the development of person re-identification (ReID) because person ReID training requires centralizing an enormous amount of data that contains sensitive personal information. To address this problem, we introduce federated person re-identification (FedReID) — implementing federated learning, an emerging distributed training method, to person ReID. FedReID preserves data privacy by aggregating model updates, instead of raw data, from clients to a central server. Furthermore, we optimize the performance of FedReID under statistical heterogeneity via benchmark analysis. We first construct a benchmark with an enhanced algorithm, two architectures, and nine person ReID datasets with large variances to simulate the real-world statistical heterogeneity. The benchmark results present insights and bottlenecks of FedReID under statistical heterogeneity, including challenges in convergence and poor performance on datasets with large volumes. Based on these insights, we propose three optimization approaches: (1) We adopt knowledge distillation to facilitate the convergence of FedReID by better transferring knowledge from clients to the server; (2) We introduce client clustering to improve the performance of large datasets by aggregating clients with similar data distributions; (3) We propose cosine distance weight to elevate performance by dynamically updating the weights for aggregation depending on how well models are trained in clients. Extensive experiments demonstrate that these approaches achieve satisfying convergence with much better performance on all datasets. We believe that FedReID will shed light on implementing and optimizing federated learning on more computer vision applications.
Weiming Zhuang
Senior Research Scientist
My current research interests include multimodal foundation model, federated learning, and computer vision applications.