Abstract
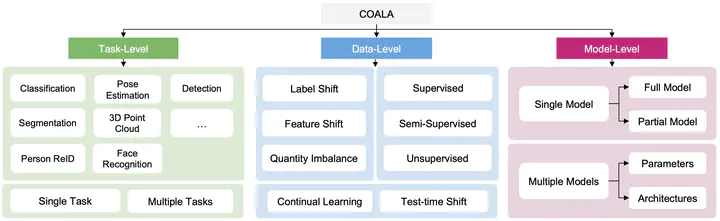
We present COALA, a vision-centric Federated Learning (FL) platform, and a suite of benchmarks for practical FL scenarios, which we categorize as task, data, and model levels. At the task level, COALA extends support from simple classification to 15 computer vision tasks, including object detection, segmentation, pose estimation, and more. It also facilitates federated multiple-task learning, allowing clients to train on multiple tasks simultaneously. At the data level, COALA goes beyond supervised FL to benchmark both semi-supervised FL and unsupervised FL. It also benchmarks feature distribution shifts other than commonly considered label distribution shifts. In addition to dealing with static data, it supports federated continual learning for continuously changing data in real-world scenarios. At the model level, COALA benchmarks FL with split models and different models in different clients. COALA platform offers three degrees of customization for these practical FL scenarios, including configuration customization, components customization, and workflow customization. We conduct systematic benchmarking experiments for the practical FL scenarios and highlight potential opportunities for further advancements in FL.
Weiming Zhuang
Senior Research Scientist
My current research interests include multimodal foundation model, federated learning, and computer vision applications.